As part of last month’s .NET in London event over in our London office, Lead Solutions Architect Jhai Watson and Test and Technical Lead Kelvin Harrison discussed SEFE’s ongoing work to create a new centralised platform to optimise its approach to fundamental data, and what that means for traders. It accompanies our article on market modelling, the other topic which was discussed at the same event in September.
A great opportunity for anyone who missed out on the day’s proceedings, below Jhai and Kelvin offer their insights into how this new platform will aid in the cataloguing, observing, monitoring and delivery of data to traders – with a particular emphasis on data quality and low latency.
Fundamental data’s role in market modelling
With market modelling, success is dependent on the data going in. The better the data that goes in, the better the insights that come out, or as Jhai says, “we want to avoid the garbage in, garbage out problem”.
One of the main types of data used in these models is fundamental data i.e. data that has the power to influence prices and includes things as diverse as:
- Weather
- Gas
- Dam capacity
- Panama Canal ship queue times
- Power station scheduled maintenance
- Sales of electric kettles
This kind of data needs to be collected and made available to the models and processes used at SEFE. Real-world examples of these processes include:
- A process to forecast the market
- A process to prepare data to make trading decisions
- A process that calculates risk
- A process to calculate financial positions
- A process to generate reports for clients
- A process to generate regulatory reports
- A prototype idea where requirements are not yet formulated until the data is in place
Fundamental data: how it used to be for us
“After we collected many examples of data for the above,” Kelvin says, “we entered the dark times…”
He continues, “Our estate grew out of control to where we now have a multitude of databases, file shares and random collections of data – often not organised or collated.
We now collect 500 sources and 100,000 series of data, all from the likes of market data providers, internal systems and people, or websites on the internet. As such, this all presents a significant risk and cost to our operations. It also presents us with several questions: how do we operate? How do we manage and maintain? How do know when something is broken and how do we deliver data to our customers?”
These questions, and the risks involved in the current system, have led the team towards working on an alternative, an optimised data platform that will answer these pain points.
Towards a new data platform
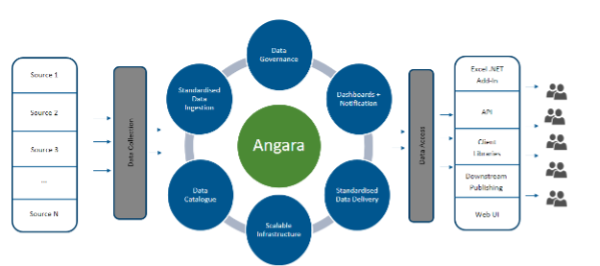
Jhai says, “Angara is our centralised data platform which we’re currently building in order to solve our data problems”.
Through Angara, the team will be able to achieve the following:
- The ability to take on data quickly: “Our business needs to be able to react to changes within markets, analyse movements and research alternate strategies at speed,” says Kelvin
- A catalogue of data: “We’ll be able to find data in our platform, without duplication”
- The ability to know customers: “We need to know who to notify if a data series has issues, and be able to decommission a series if it is no longer used,” Kelvin says
- Notifying consumers about the state of data: “We’ll provide proactive notifications for data arrival, lateness or data quality issues. This will stop users from having to check the state before running their process”
- A standardised way to deliver data to our users: “This will provide a simple access method for getting data rather than having to connect to a series of databases or file shares”
- The ability to scale: “Our data needs are pretty ravenous, so we need to be able to handle growing volumes more readily.
Angara’s architecture, Jhai and Kelvin mention, is built around components that meet these requirements.
Angara’s architecture in more detail
“With Angara, we’ll keep all data forever,” says Jhai. This means keeping all versions of data as it changes over time. “Because of this, we’ll be able to look at both its history, and the journey through history so our models can see how that data has progressed over time.
“And while this poses some significant problems regarding volumes and performance, we’ve been confident that we’ll overcome these hurdles with strong engineering and moving to a cloud environment with elastic scaling”.
This toolset consisted of:
- .NET
- js
- RabbitMQ
- MongoDB
- SQL Server
There are good reasons for these selections. Namely, SEFE has a long history and strong experience with the Microsoft toolset and RabbitMQ. The team also adopted MongoDB for their NQSQL database due to its scalability and flexibility in taking on data of various forms without needing to manage scheme changes in the database.
The team weren’t as familiar with Mongo, which meant getting up to speed with it.
- Mongo’s Database
In terms of its database, the team found they could build standard queries against their data since they had many different payload types. With this standard schema and multiple payload types, the team could manage the complexity in testable .NET code.
“Not only does our data have varying shapes, it also has varying sizes,” Jhai says. “We looked at one of our most extreme cases where he had a single payload of timeseries data spanning 2 years with 1-hour granularity that provided 17520 datapoints. We decided to do payload compression to avoid hitting Mongo’s maximum 16MB document size – which would otherwise require splitting a single payload into multiple documents. This provided us with fewer documents in Mongo, as well as a smaller database footprint”.
- Mongo’s Data Storage
“In production uses of our system, our theoretical use cases were challenged,” says Kelvin, “so over time, with our system being used in production, we started to notice a slowdown in query speeds due to Large Due Queries.
“Some of these involved loading tens of thousands of documents, decompressing tens of thousands of payloads into memory, processing this data and returning the result”. This meant high CPU usage due to decompression and high memory usage due to having to load everything into memory – and process it all at once.
This was further compounded by large payloads. Compressing these meant Mongo couldn’t interrogate the payload, and so the team were unable to optimise their query in order to reduce the amount of data returned to the service for processing.
- Messaging
“We adopted the .NET common library for messaging. However, our expectations of how this library worked didn’t align with what you’d normally expect,” says Jhai. “Usually, when queue of messages pass between services and being processed, each message is processed and acked before it moves on”.
However, what we were doing was auto acking every message and bringing it into memory and our internal messaging hub to then be processed on all separate threads all at the same time.”
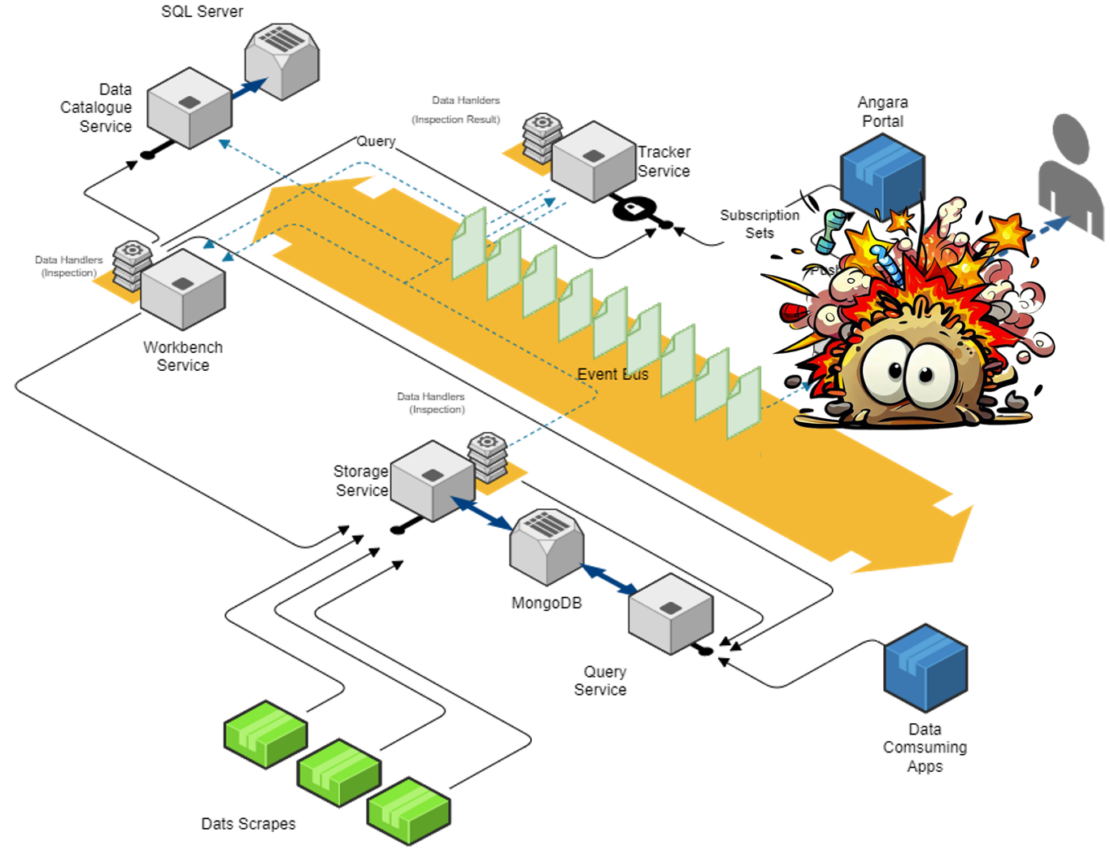
“As you can imagine, with such high volumes and several services all going on at once, the servers’ memory and CPU hit high loads for long periods of time,” Jhai notes. The high load on these production boxes meant that services were having to be started on a weekly basis, a process that Jhai linkes to “constant Whack-a-Mole”. These outages, along with the auto acking, meant the team didn’t know how much data they’d lost, which meant having to constantly reload everything that occurred during the outage window. “This continued for months until we could update our implementation to fix this,” says Kelvin.
- Testing
“We needed a way to be able to test our worst-case scenarios and get ahead of the curve so we could understand our systems’ limitations and check for improvements”, Kelvin says.
“One of these scenarios was testing the long and short day – or the switch between summertime and wintertime. If it isn’t handled correctly, this time shift can cause all sorts of issues across the business, like trades being misaligned with prices, for example”.
“Angara has the ability to set any time, so we can effectively time travel between these times and avoid the problems the time shift has the potential to cause”, says Kelvin.
A huge thanks to Jhai and Kelvin for their insights into the upcoming platform. To explore SEFE’s latest IT and data roles, head to their jobs page here.